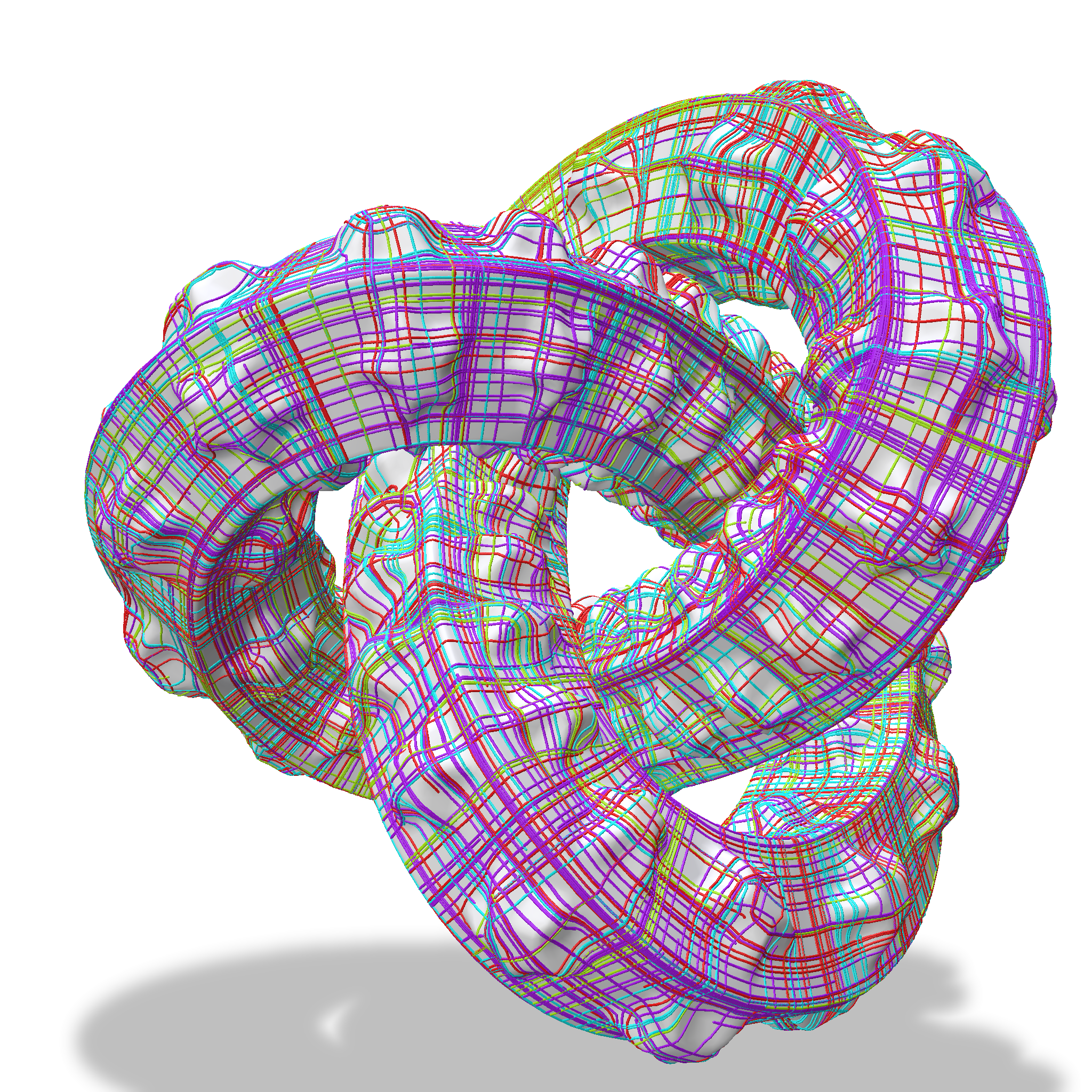Look Both Ways Before You Cross: Lifting Cross Fields From 2D Visual Priors
🖱️ To interact with the 3D models, Scroll to zoom, hold Left Click + drag to rotate, and hold Right Click + drag to translate.
🔍 To zoom in on any visualization, Click the image or model to open it in a popup.
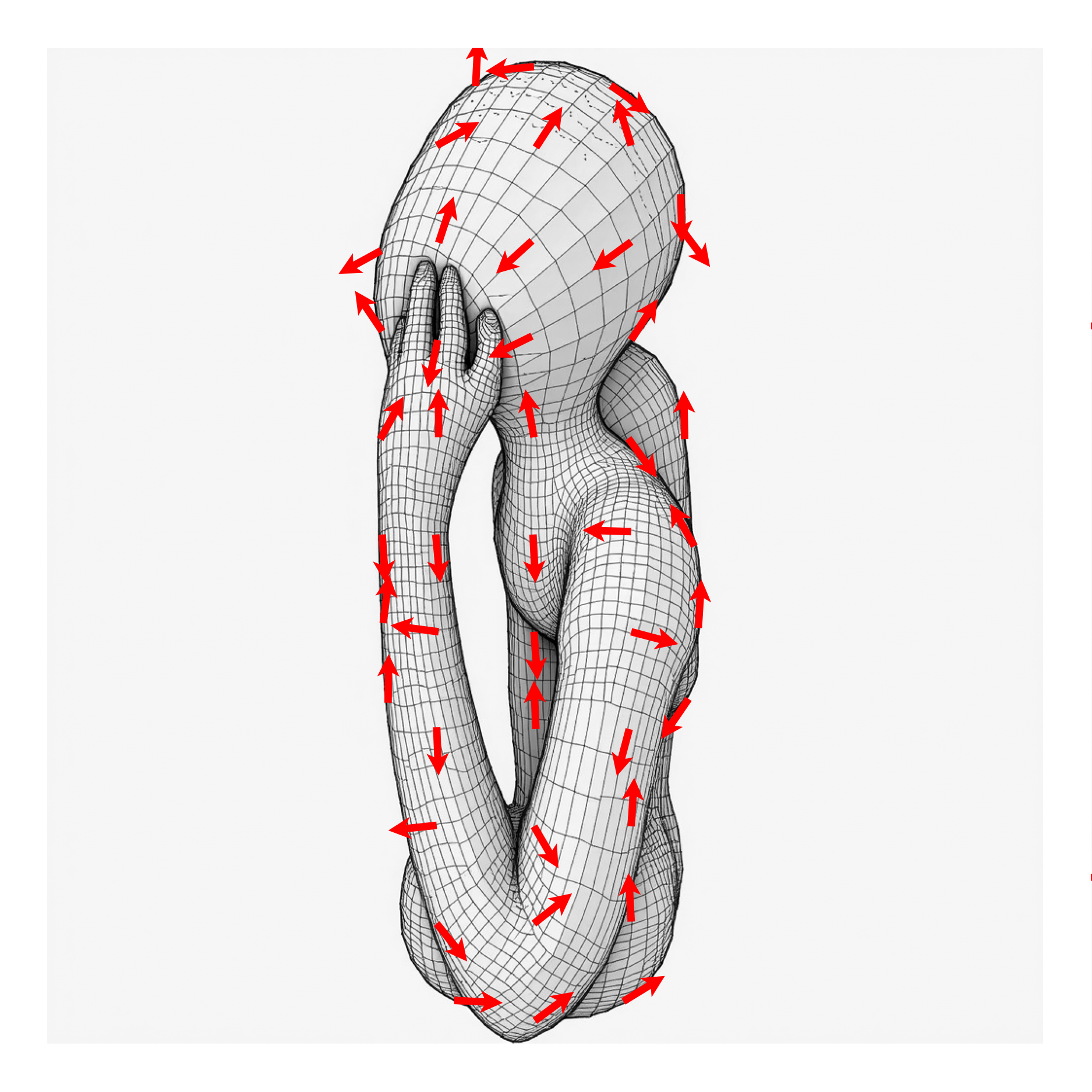
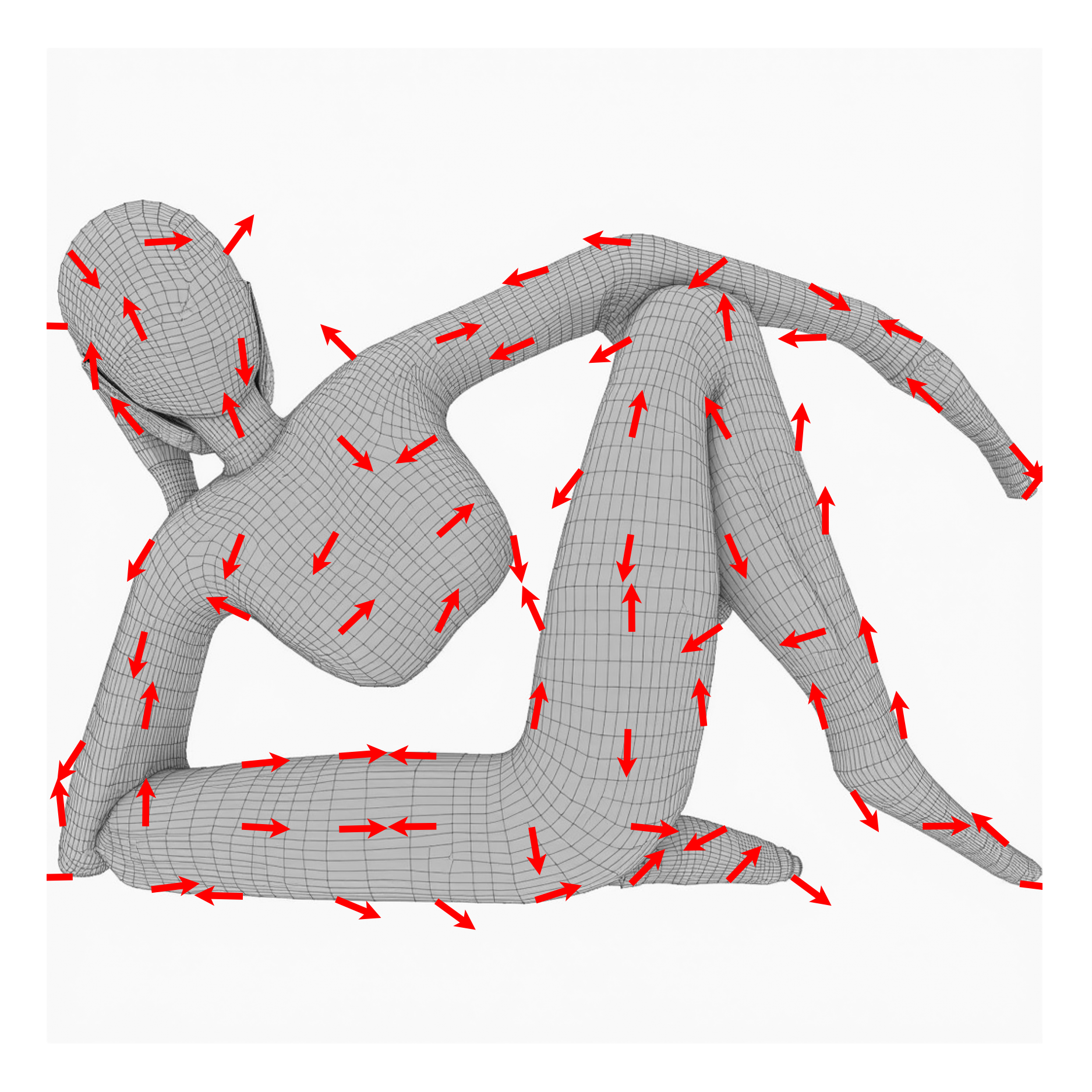
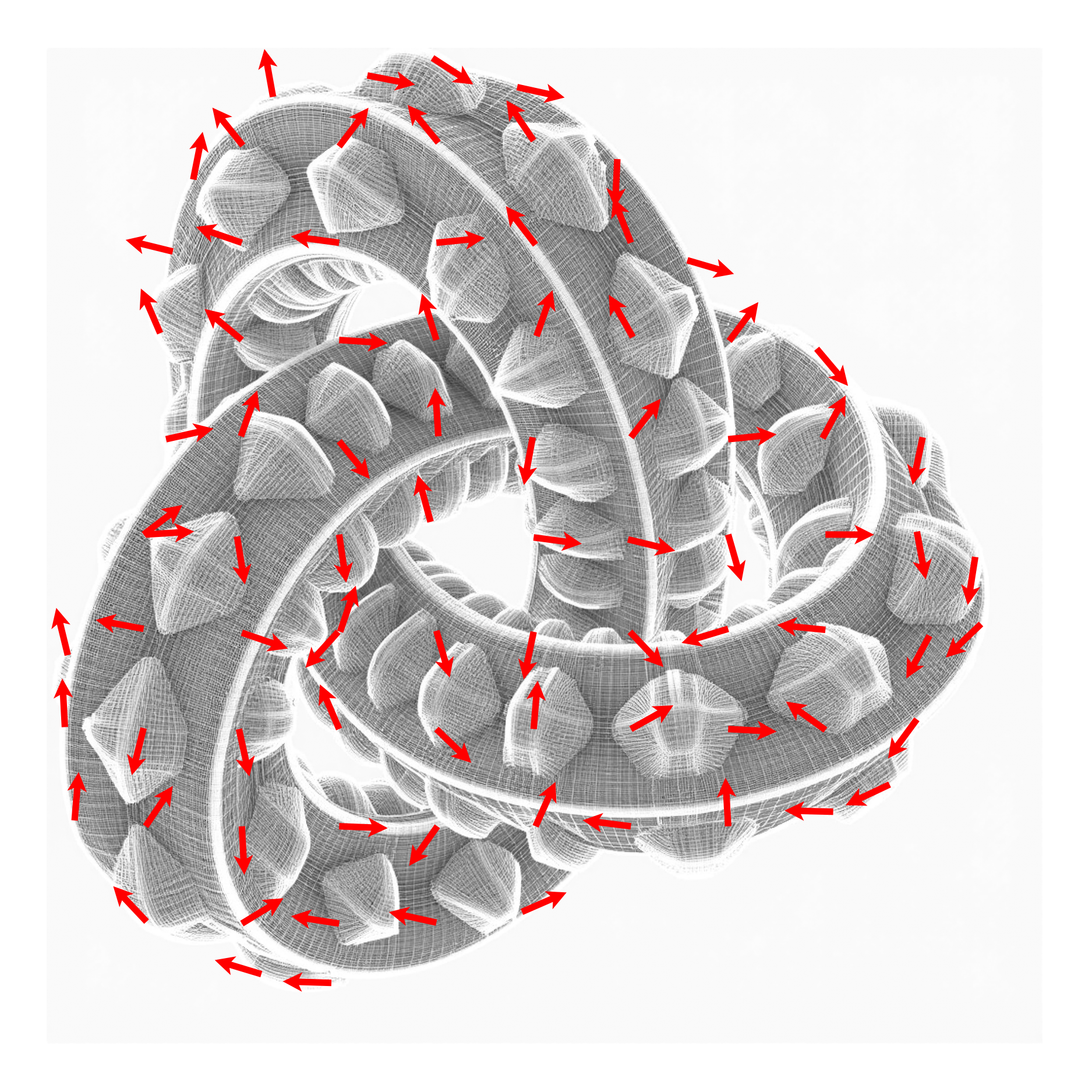
Our method CrossLift produces feature-aligned quad meshes
(blue) using directions
(red) extracted from image-space quad
alignment priors (gray). These priors
encode both semantic and geometric information about the shape, allowing
our resulting quad meshes to capture meaningful semantic features
(e.g., the facial features of the cat) while adhering to local geometric
cues such as the sharp ridges of the Lego brick.
Method
Method Overview. Taking a mesh as input, our method renders depth from
multiple views using these to condition a 2D generative model which produces
multi-view images depicting a quad pattern on the mesh. We extract the alignment
directions from these images using pixel gradients and project those directions
back to the 3D surface. Here, we interpolate using two solves, first per-view to
accumulate the directions into a cross field over the faces and second to
interpolate these multi-view cross fields into a single smooth cross field for the
mesh.
Gallery
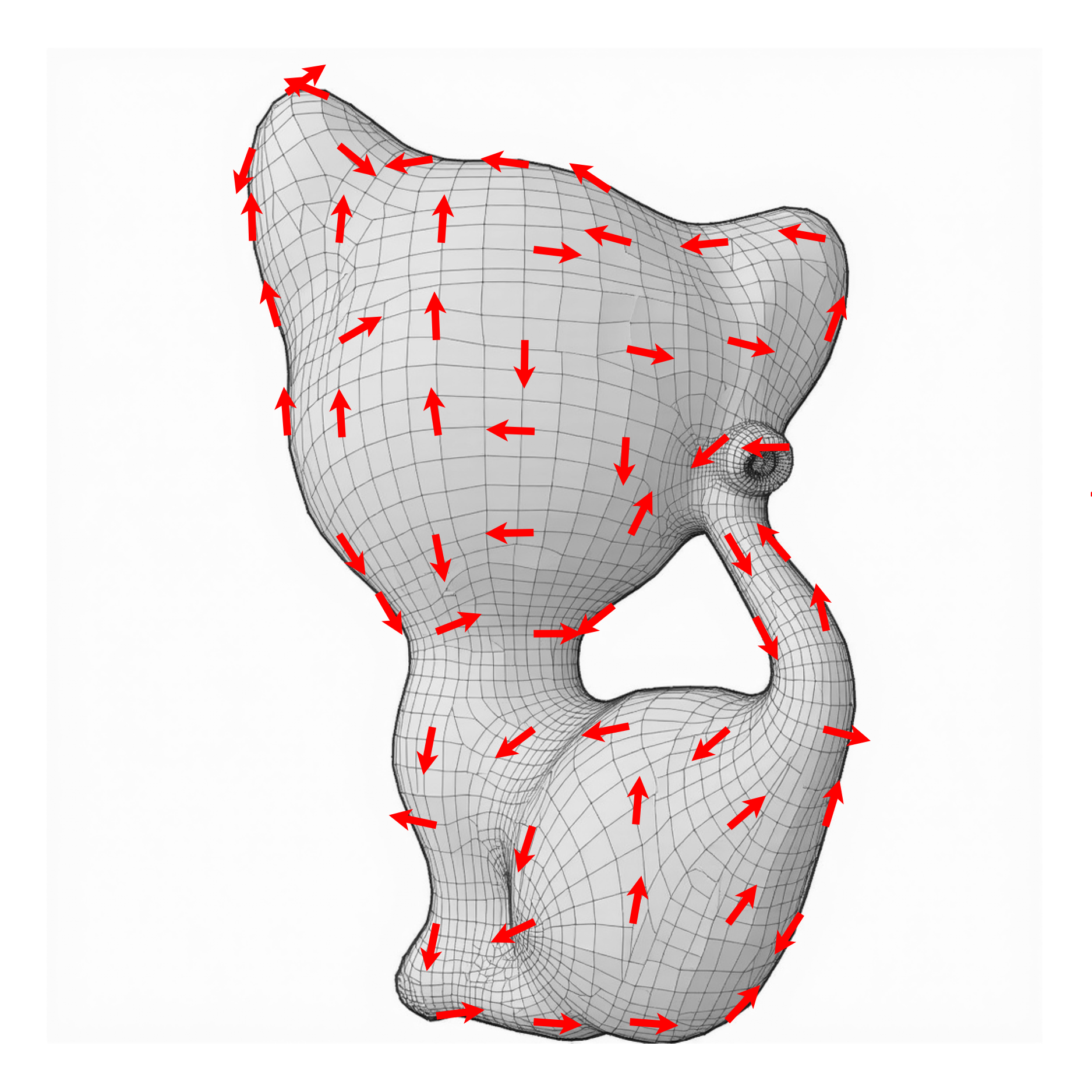
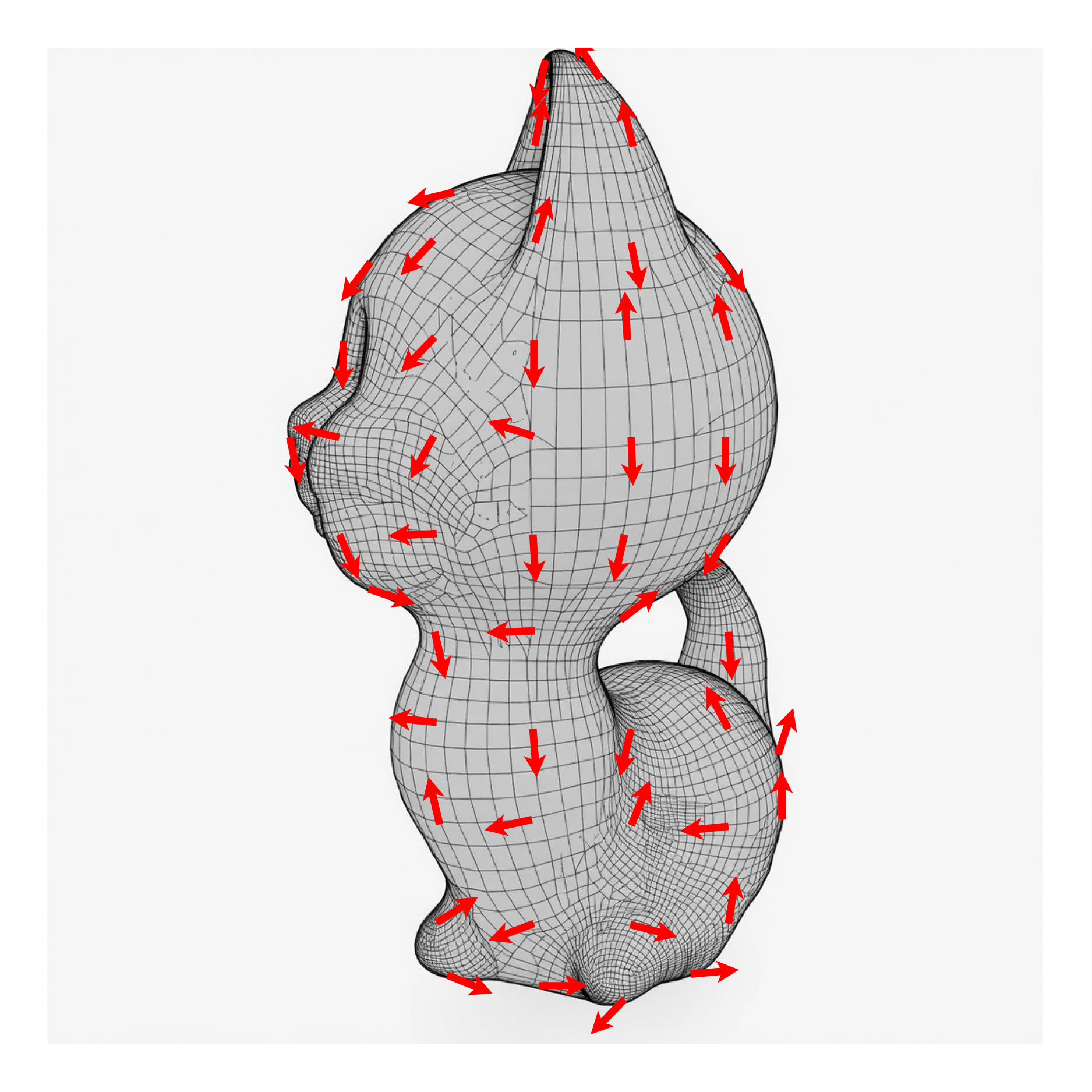
Gallery. Our method produces desirable quads for a variety of shapes, both
organic and manufactured. The quad lines do not just follow geometric features:
our method generates quads whose edges follow semantic feature lines of the shapes
through our use of text-to-image priors and without any 3D interaction.
Applications
Texture-Aligned Quads
Texturew/o Texturew/ Texture
Hand-Drawn Coarse 2D Guidance
Texture-Aligned Quads. Given a textured mesh
(left), we show the 2D prior output (gray) and
final quad mesh (blue) using either untextured
(middle) or textured (right) renders of the mesh to condition our 2D prior. Using
untextured renders produces quads aligned to the features of the shape, while
using textured renders allow our method to align quads to the features in the
texture.
Hand-Drawn Coarse 2D Guidance. Our method can extract signals from coarse
hand drawn alignment directions on renders of our mesh. This 2D guidance is easy
to create and provides fine-grained control to the user without requiring any 3D
technical knowledge or skills.
Robustness
FluxGemini 3ChatGPT 5.2
Compatibility with Alternative 2D Guidance Signals. Our method is modular
and while we use Flux (left) for the results shown in the main paper, we also show
our method with alternative 2D priors Gemini 3 (middle) and ChatGPT 5.2 (right).
Our method is robust to alternative 2D guidance signals (shown in gray) producing
plausible semantically aligned quads in each case.
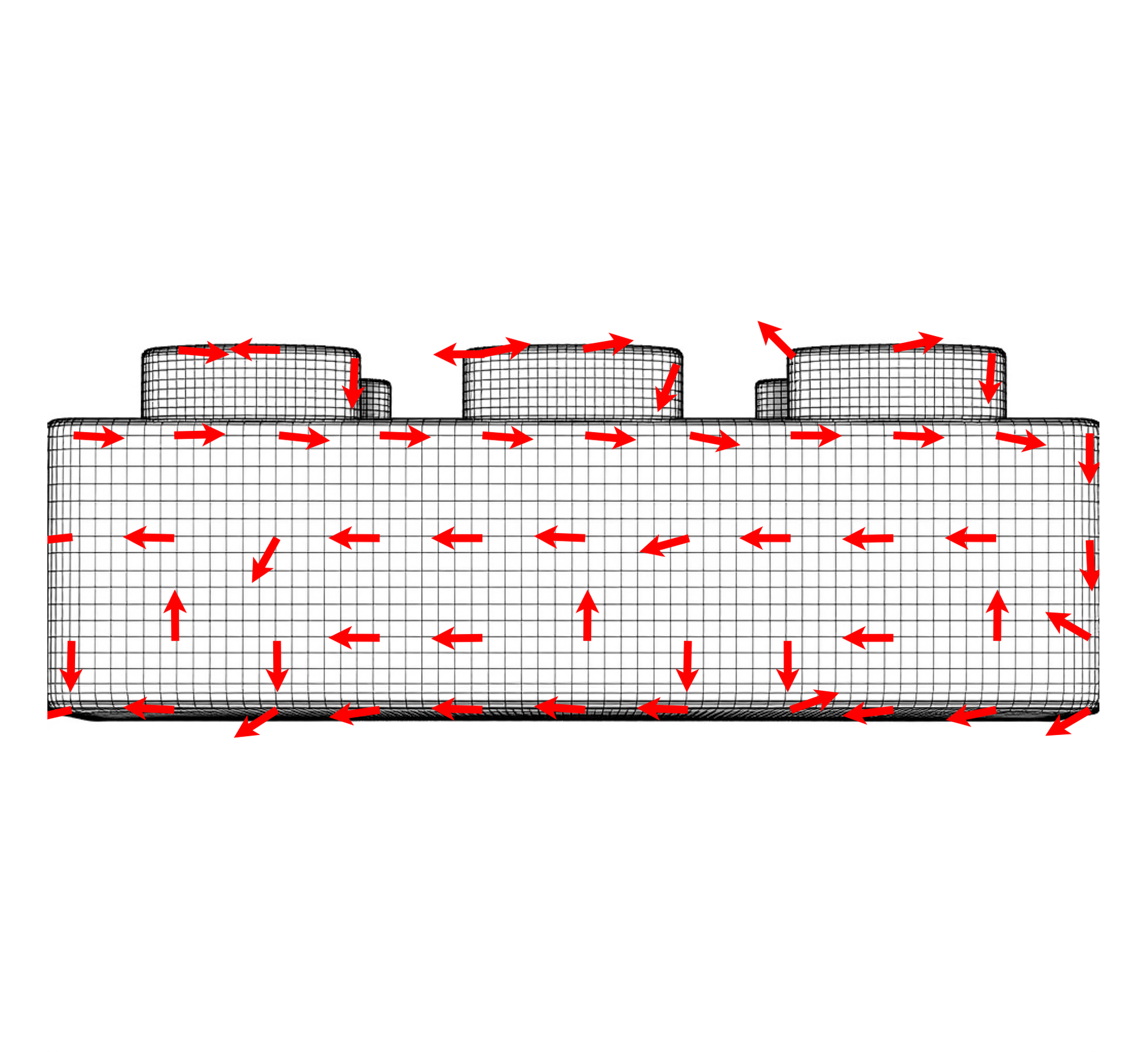
Robustness to Surface Noise. Our visually-guided method is robust to
surface noise such as the wrinkles in the tablecloth. A baseline method using
principal curvature constraints alongside a smoothness term aligns to these local
features producing undesirable edge flow and introducing additional singularities.
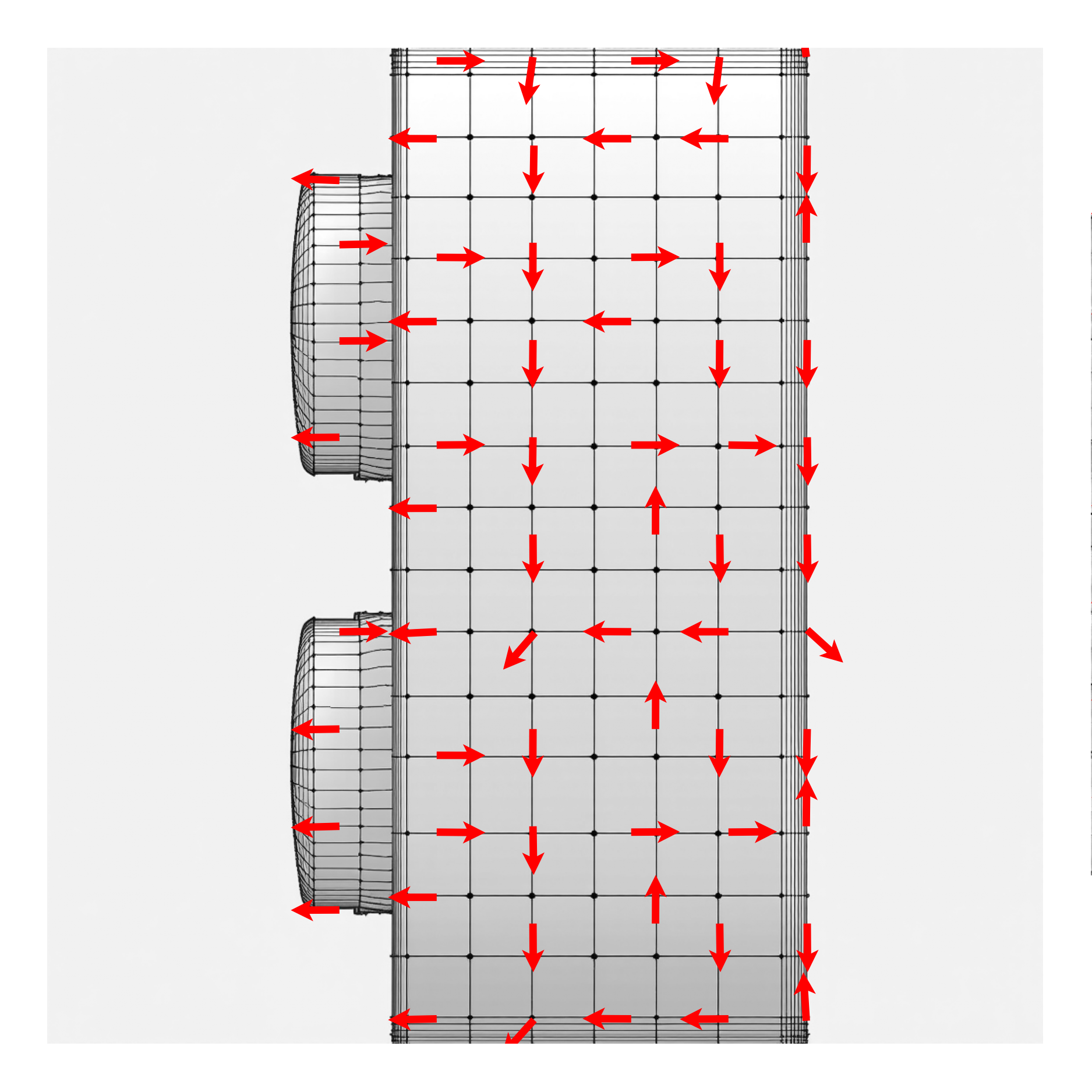
Interpolation to Non-visible Mesh Regions. Our method robustly produces a
smooth field even in regions that are not visible in the 2D views ($\ie$ the area
under the penguin's wing). Without the smoothness term ($\lambda_s = 0$), the
resulting field has holes and our quad mesh extraction fails. With this term
($\lambda_s = 1$), we are able to smoothly interpolate the surrounding field to
get meaningful values in the unseen region.
Streamlines
✨ Hover over a streamline visualization to reveal the underlying mesh.
Streamlines. We visualize streamlines of our cross field
traced across the mesh surface. These streamlines show the field alignment used to
produce our final quad meshes.
Comparison
QuadriFlowQuadWildNeurCrossOurs
Qualitative Comparison. We compare our method to QuadriFlow, QuadWild and
NeurCross. QuadriFlow and QuadWild often produce wavy edge flow, while NeurCross
tends to produce overly axis-aligned edge flow that fails to align to specific
features. In contrast, our method produces edge flow that demonstrates superior
alignment to both semantic and geometric features.
Scroll to zoom · Drag to pan when zoomed · Click anywhere to close